C#使用Xpath进行html解析
0x00.Xpath
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。 XPath 含有超过 100 个内建的函数。这些函数用于字符串值、数值、日期和时间比较、节点和 QName 处理、序列处理、逻辑值等等。
0x01.添加引用
Nuget中下载 HtmlAgilityPack,项目中引用
using HtmlAgilityPack;
0x02.Load html页面
HtmlDocument index = web.Load("http://www.sonystyle.com.cn/mysony/acafe/index.htm");
0x03.查看所需元素的Xpath
浏览器以火狐为例 打开所需网页,F12进入控制台 定位到所需元素,右键→复制→Xpath 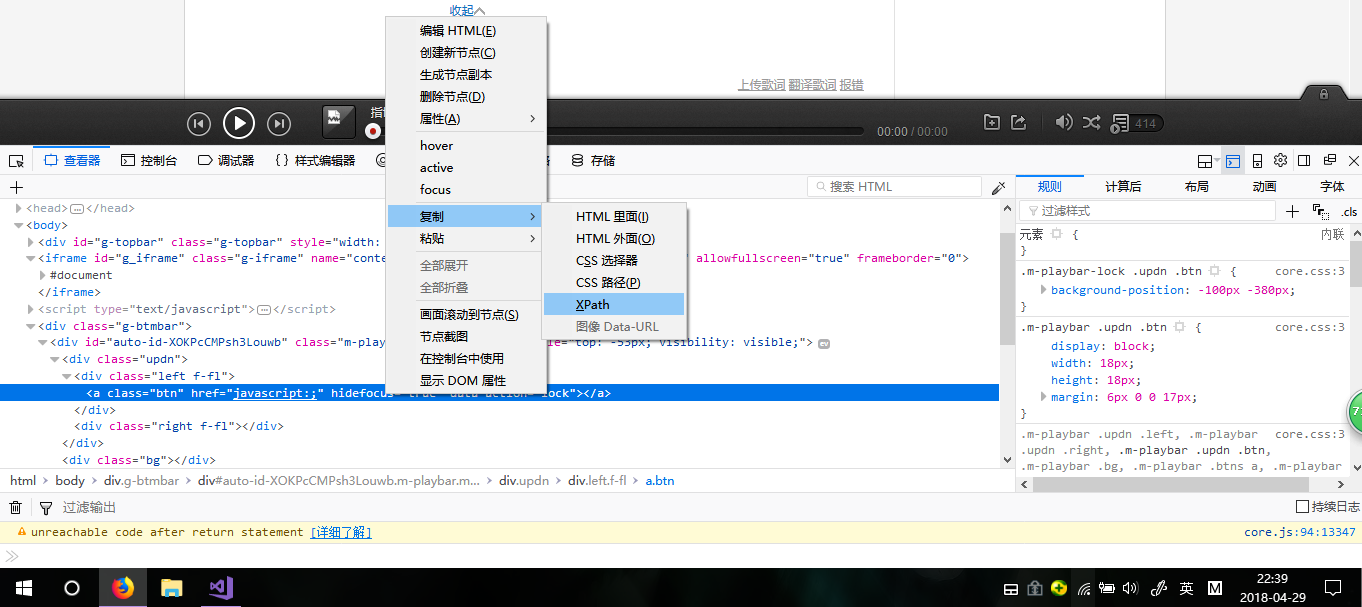 e.g:/html/body/div[3]/div[1]/div/div/div[1]/div[1]/div[1]
e.g:/html/body/div[3]/div[1]/div/div/div[1]/div[1]/div[1]
0x04.DocumentNode.SelectNodes的用法
DocumentNode.SelectNodes选择的是多个节点,需要使用集合
private List<string>list;
foreach (var sth in index.DocumentNode.SelectNodes("//ul[@class='slides']/li/a/img"))
{
list.Add(base_url + index_img.GetAttributeValue("src", ""));//获取对应元素的src值
}
//*是固定格式,*表示匹配中的元素 / 表示下一次 @表示对应的属性,如//ul[@class='slides']表示class为slides的ul元素
0x05.DocumentNode.SelectNodes的用法
DocumentNode.SelectNodes选择的是单一元素,所以需要使用该元素的绝对路径
var sth = index.DocumentNode.SelectSingleNode("//div/li/a/img");
var attribute=sth.GetAttributeValue("src", ""));0x06.更多
C#使用Xpath进行html解析
https://blog.async.website/index.php/archives/1001/